近日,实验室在多模态大模型(LMMs)知识更新领域取得了重要研究进展。研究论文“MMKU-Bench: A Multimodal Update Benchmark for Diverse Visual Knowledge”被国际顶级学术会议ICML 2026正式接收。文章第一作者为实验室博士生付保辰,通讯作者为宋维业、万熠教授,山东大学为第一完成单位。
ICML是机器学习领域历史最悠久、规模最大、影响最广的顶级学术会议之一,也是中国计算机学会CCF推荐的A类会议,该论文的发表体现了实验室在人工智能前沿方向的研究实力与创新能力。
研究背景
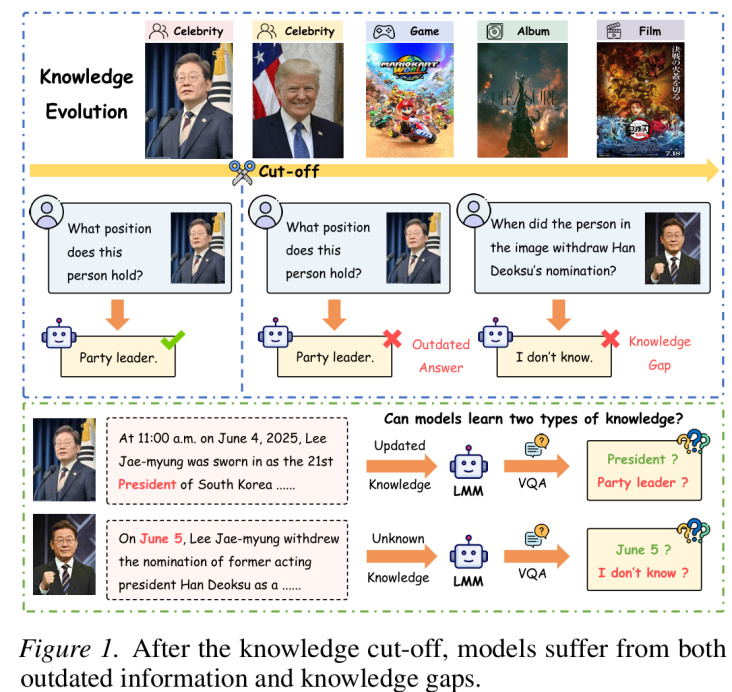
随着现实世界信息的不断更迭,多模态大模型在预训练阶段获取的参数化知识往往会随时间失效或变得陈旧。现有的多模态知识更新研究大多侧重于让模型学习“全新的、未见的知识(Unknown Knowledge)”,而忽略了更为棘手的场景:如何纠正和更新模型已经掌握但已发生变化的“更新知识(Updated Knowledge)”。
此外,目前的评估手段多局限于单一模态(如仅文本或仅图像),缺乏对多模态模型在知识更新后,其跨模态推理是否保持一致性的深度分析。同时,频繁的知识更新是否会诱发模型原有通用能力(如数学推理、OCR等)的“灾难性遗忘”,也是当前学术界亟待解决的关键难题。
研究方法
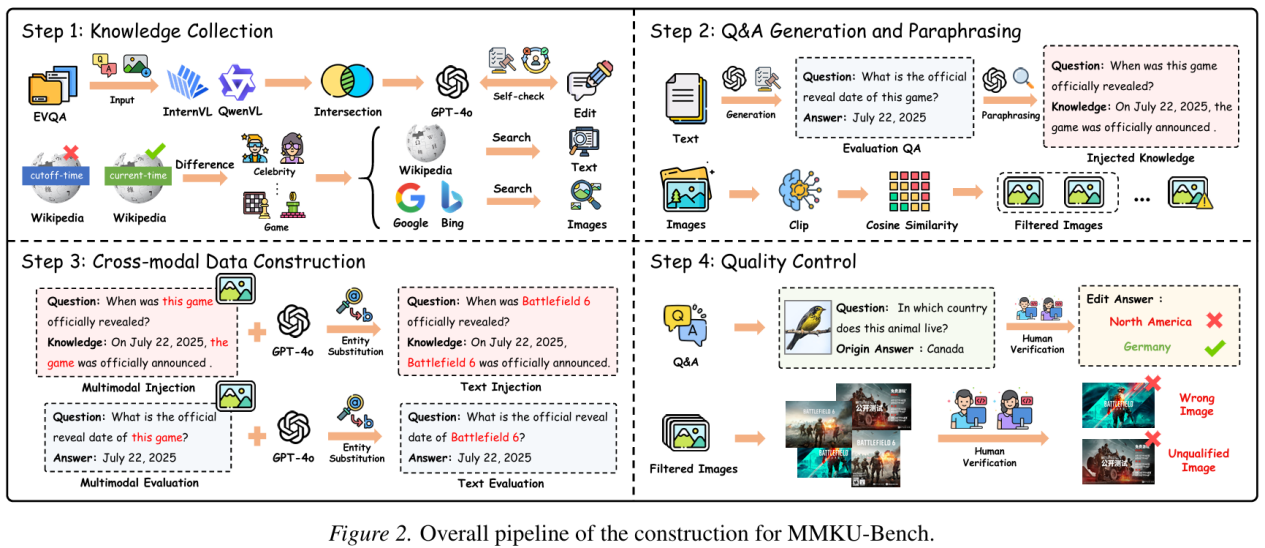
为了填补上述空白,本文构建了包含超过2.5万个知识实例、4.9万张图像的大规模基准测试MMKU-Bench。研究的核心创新点包括:
1.知识属性的解耦:对比分析“更新知识”与“未知知识”在注入过程中的差异,揭示了模型在处理更新知识时表现出的强大“知识惯性”。
2.多样的评估维度:除了评估知识注入精度外,还引入了通用能力评估(评估知识更新对基础模型能力的影响)和跨模态一致性评估(确保新知识在不同模态表达下的一致性)。
3.统一的评估框架:系统性地评测了监督微调(SFT)、人类反馈强化学习(RLHF)以及多种主流的知识编辑(KE)算法在多模态场景下的表现。
研究结果
实验结果显示,当前的先进多模态模型在知识更新方面仍面临严峻挑战。研究发现,虽然SFT和RLHF能够显著提升新知识的注入率,但往往会导致模型基础能力的严重退化;而现有的知识编辑方法在处理大规模连续更新时表现疲软。此外,研究揭示了模型在更新知识后,往往无法在跨模态推理中实现逻辑自洽,表明当前多模态对齐机制在语义更新层面存在结构性缺陷。
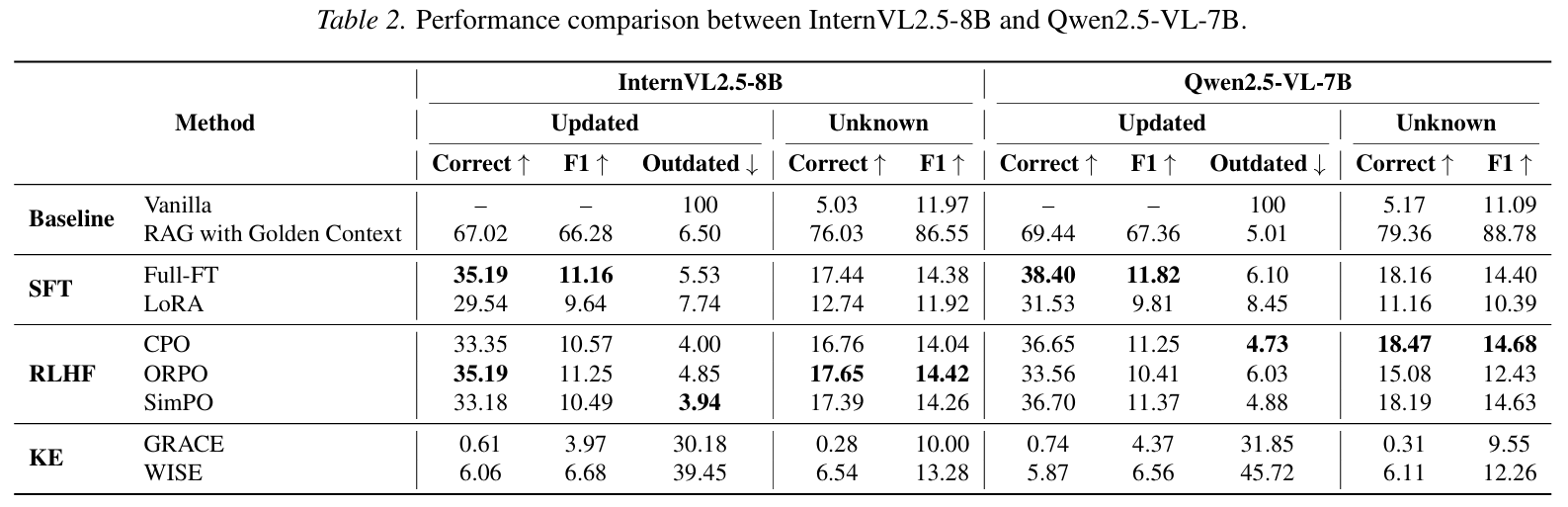
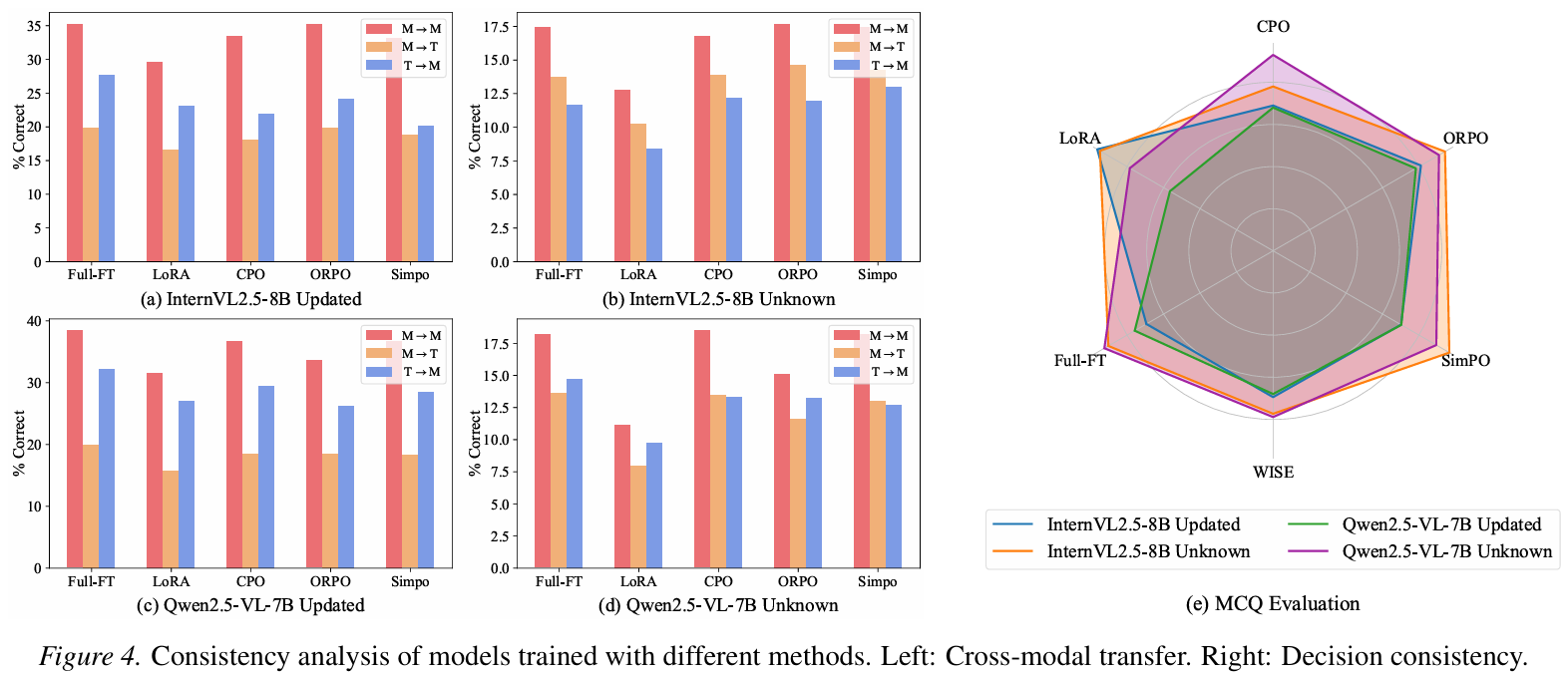
本研究不仅为多模态大模型的知识更新提供了评估基准,也为未来设计更稳健、具备持续学习能力的模型和方法提供了重要的实验依据和理论指导。目前,MMKU-Bench的相关数据集与代码已在GitHub(https://github.com/baochenfu/MMKU-Bench)开源,旨在推动多模态大模型领域的进一步发展。