近日,实验室在医学影像智能分析领域取得了新的研究成果,论文“DLSANet: A dual-path learnable structure-prior attention network for retinal layer segmentation”被Biomedical Signal Processing and Control(中科院二区期刊,IF=4.9)期刊正式接收,作者包括刘恩予、徐睦浩、宋维业教授等。
该研究提出 DLSANet 网络,通过双路径可学习结构先验与多域特征增强,有效解决了视网膜 OCT 分割中结构不一致与噪声敏感两大难题,实现了精准、鲁棒的自动化层分割。
研究背景
视网膜层分割是青光眼、糖尿病黄斑水肿(DME)等致盲眼病早期诊断与病程监测的核心依据。光学相干断层扫描(OCT)作为临床 “金标准”,可无创、高分辨地呈现视网膜分层结构。但临床自动化分割仍面临两大瓶颈:
1.现有模型对视网膜解剖先验建模不足,分割结果易出现层断裂、错位、跨层重叠等结构不一致问题;
2.OCT图像固有的散斑噪声会降低层间对比度,模糊边界,导致分割精度下降。
传统方法多通过后处理或损失函数引入结构约束,未能在特征学习阶段真正理解解剖结构,在病理变形与强噪声场景下稳定性不足。为此,团队将可学习解剖先验与多域特征增强深度融合,提出轻量化、高精度的DLSANet分割框架。
研究方法
本研究提出DLSANet双路径可学习结构先验注意力网络,以核心DLSA模块为创新支撑,通过先验建模与引导组件学习视网膜解剖结构约束、多域特征增强组件抑制OCT散斑噪声并保留细节边界,在特征学习阶段同步实现结构一致性与抗干扰能力提升。模型全程端到端可训练,参数仅4.1M,兼顾精度与临床部署效率。
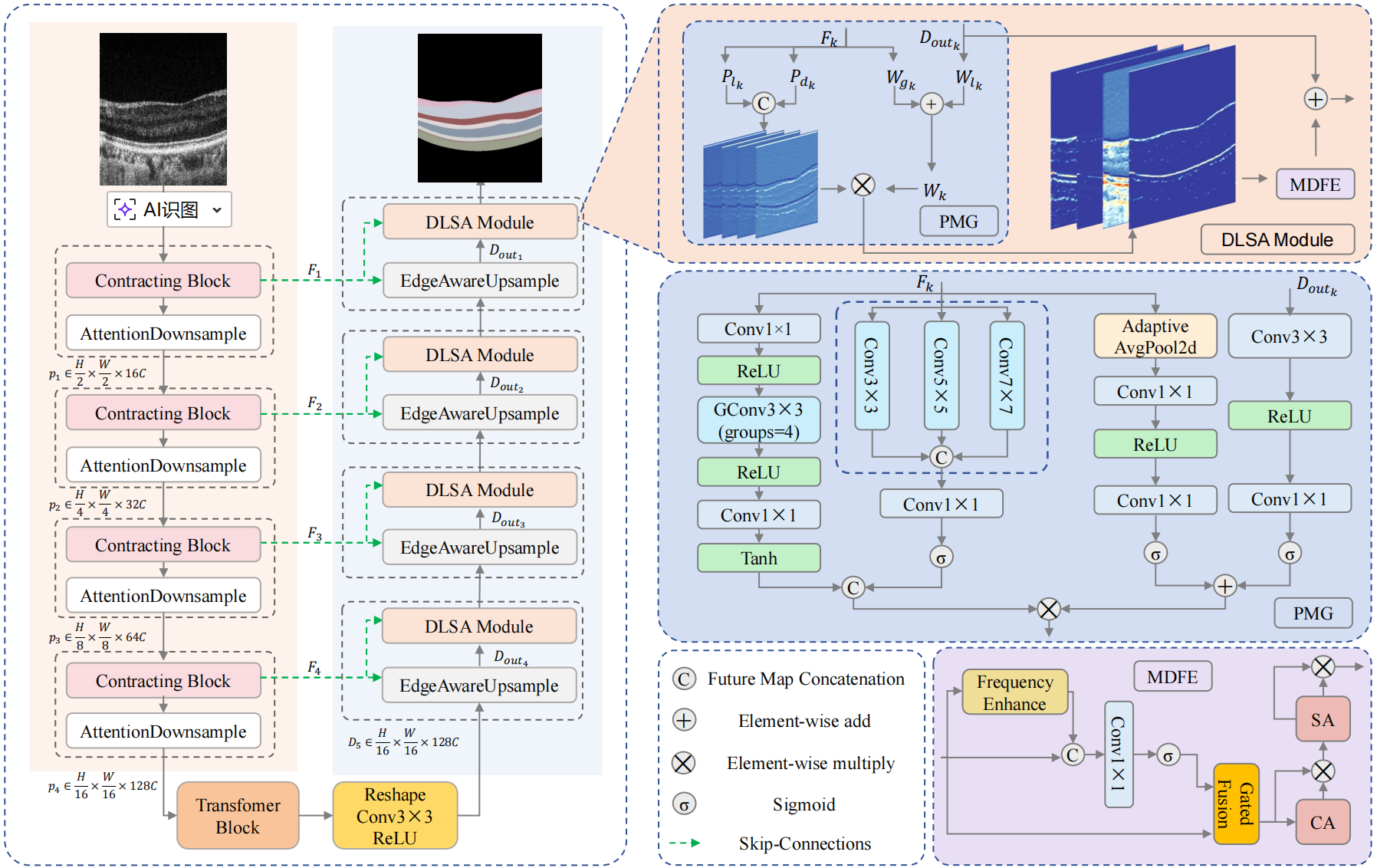
图1 网络框架图
研究结果
团队在自建健康数据集Retina500、两个公开病理数据集(DME、Glaucoma)上开展全面对比实验,与U-net、Attention Unet、TransUnet、LightReSeg等主流方法进行验证。结果表明所提方法在 mIoU、Acc、mPA、HD95 等关键指标上均达到最优水平,分割结果连续准确、对散斑噪声与病理病变鲁棒性强,同时模型仅4.1M参数,轻量高效、具备临床部署潜力。
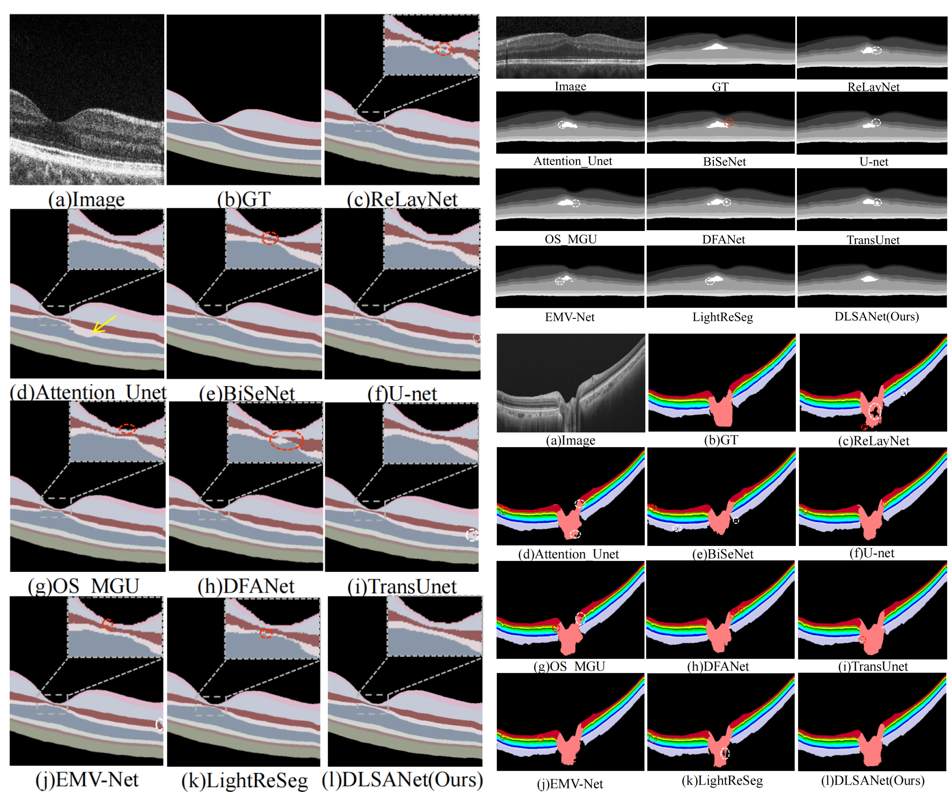
图2 定性分析对比
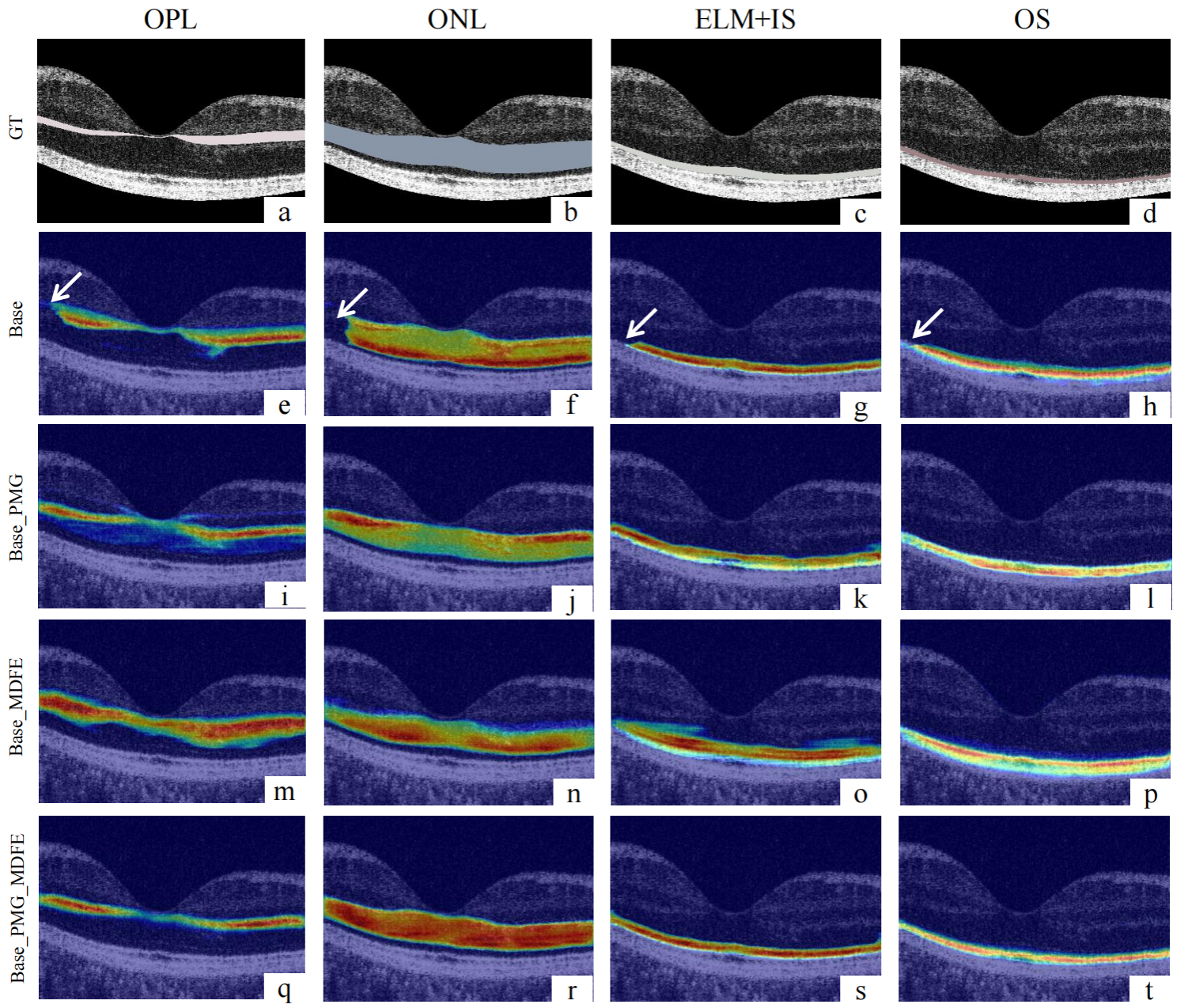
图3 实验结果可视化图
本研究首次将双路径可学习解剖先验嵌入解码器,实现结构先验指导特征学习的端到端分割,从机制上解决视网膜层分割不一致与噪声敏感问题。成果不仅提升了OCT视网膜层分割的精度与鲁棒性,更为眼科AI辅助诊断、大规模筛查、长期随访提供标准化、可落地的算法支撑。