导读
近年来,相较于结构异常检测,逻辑异常检测正变得愈发具有挑战性。现有的基于编码器-解码器的方法通常假设压缩过程能有效抑制逻辑异常向解码器的传递,从而将输入压缩到低维瓶颈中。然而逻辑异常存在特殊难点:虽然其局部特征常与正常语义相似,但整体语义却显著偏离常规模式。得益于神经网络的泛化能力,这些异常语义特征可通过低维瓶颈传播,最终导致解码器以误导性的保真度重建异常图像。为应对这一挑战,本研究提出一种基于正态性先验的多语义融合网络进行无监督异常检测。不同于直接将压缩后的瓶颈输入解码器,我们在重建过程中引入了正常样本的多语义特征。具体而言,首先通过预训练的视觉-语言网络提取正常案例的抽象全局语义,随后构建可学习的语义代码本,通过向量量化存储正常样本的代表性特征向量。最后将上述多语义特征融合后作为解码器输入,引导异常重建过程趋近正常状态。该成果在国际知名期刊《IEEE Transactions on Instrumentation and Measurement》(TIM)上发表题为《Normality Prior Guided Multi-Semantic Fusion Network for Unsupervised Image Anomaly Detection》的学术论文。《IEEE Transactions on Instrumentation and Measurement》期刊是仪器仪表和工业智能检测领域的国际顶级期刊之一,最新影响因子为5.9。徐睦浩、周雪莹为共同第一作者,指导老师为牛四杰、冯光、宋维业。
研究背景
图像异常检测在工业视觉检测、医疗图像诊断、道路安全监控等场景中具有广泛应用价值。当前主流的异常检测方法大多采用编码器-解码器框架或记忆库机制,依赖于正常样本的重建误差来发现异常区域。然而,面对语义层面的“逻辑性异常”(如物体错位、数量错误等),传统方法因仅处理局部结构信息而难以有效识别。尤其在无监督设置中,缺乏异常标签指导,使得模型更难区分高层语义偏离的异常模式。
研究方法
该研究聚焦于无监督图像异常检测中的结构性异常与逻辑性异常难以统一建模的问题。现有方法普遍在逻辑异常检测方面存在泛化不足、语义模糊等挑战,尤其在复杂工业场景中表现受限。针对上述问题,论文提出了一种融合语义先验的多语义特征重建框架,如图1所示,创新性地引入了视觉-语言模型(CLIP)提取图像的全局语义先验,并通过向量量化构建多层语义码本,在解码过程中引导重建结果向“正常”语义靠拢,从而有效抑制异常信息的传播。

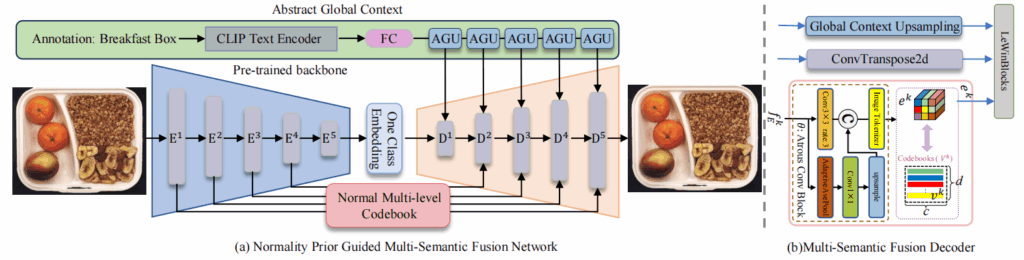
图1 方法模型图
研究结果
该方法在多个工业数据集上均取得了显著的性能提升。特别是在涵盖结构与逻辑异常的MVTec LOCO AD数据集上,提出的方法在像素级sPRO指标上超越现有最先进技术5.7%,图像级AUROC提升2.6%,方法的定性结果如图2所示。此外,在传统的MVTec AD和BTAD数据集上也展现出强大的泛化性能与定位精度。

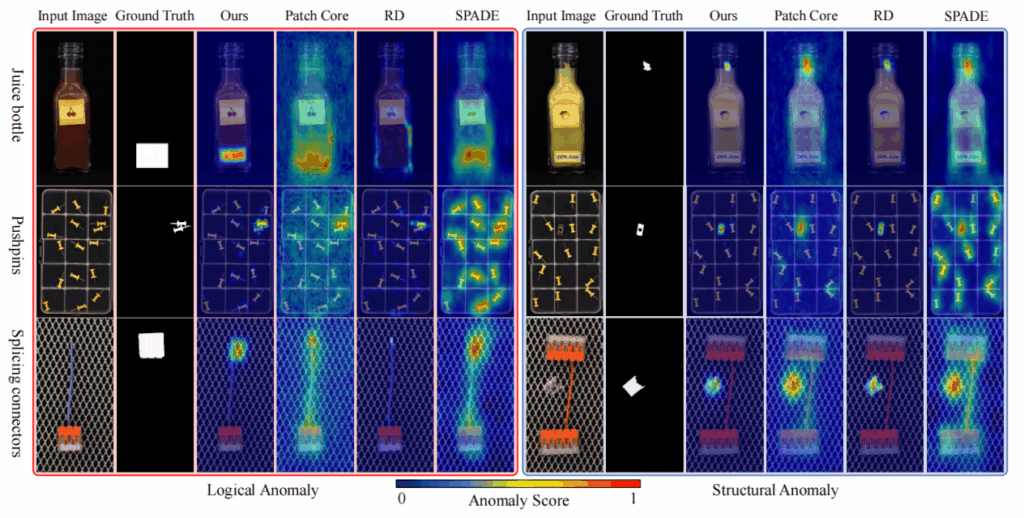
图2 方法定性结果图
结论
本研究展示了在无需异常数据监督的前提下,如何通过正常性语义先验引导,实现对复杂异常的准确感知与定位,推动了图像异常检测方法向“语义理解+结构建模”深度融合的方向发展,为工业智能检测和医学图像分析等领域提供了新思路与技术支撑。